Object Permanence in Videos: DNN Performance vs. Human Ability
Publication in IEEE and Class Project for 9.60: Machine Motivated Human Vision
IEEE Conference Proceeding
introduction
This was a project originally made as our final project for 9.60 (Machine Motivated Human Vision), which was one of my favorite classes at MIT. The main goal of this class (and project) was to explore how we can use our understanding of machine vision to drive understanding of human vision, and use our understanding of human vision to push forward the development of machine vision.
The primary motivator behind choosing this project topic was that at the time, object permanence and partial object recognition was big problem in machine vision, and not many large datasets supported exploring this problem. For example, ObjectNet was one of the first datasets that took images of objects from different angles and rotations, exposing how hard of a problem this is for many vision models. However, there weren't many datasets that explored testing object occlusion, which can also be a large problem for vision models. This can have severe consequences if not tested properly, such as with self driving cars and other innovations that aim to blend into our world.
Another aspect that we wanted to explore is how this model would perform compared to humans doing a similar task. Although most adult humans have an understanding of object permanence, this skill is developed in early childhood. Humans are not born with the ability to understand that an object is still the same partially covered and that it still exists when fully covered.
Summary
This project involved three main parts: the machine vision model, creating a dataset, and running a human study.
The final model architecture is as follows:
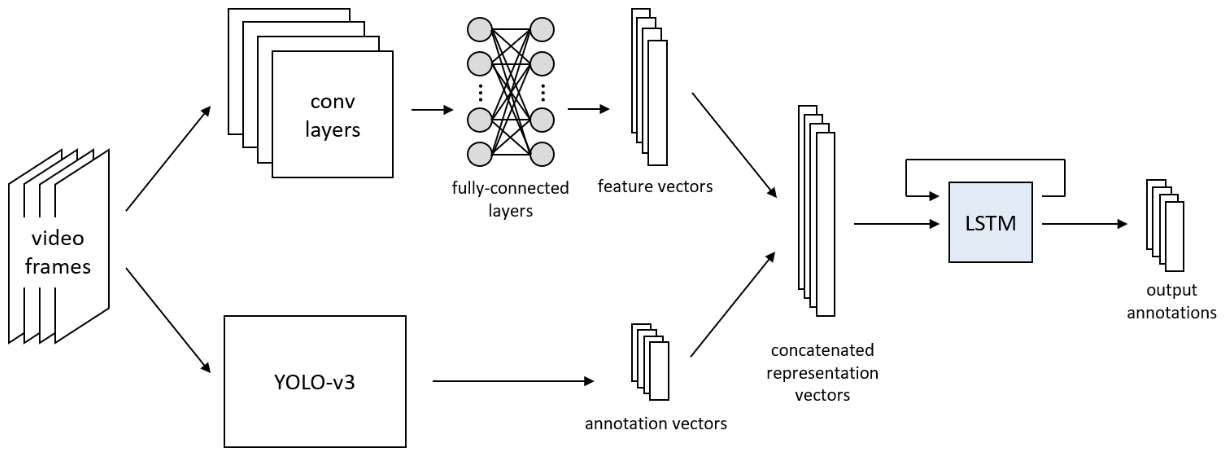
For this problem, we needed a dataset that involved short videos/image series that involved an object go from no occlusion to full (or almost full) occlusion. Since we had a few short weeks to finish this project, we opted to create our own dataset that involved various shapes that then either moved behind a black bar or had a black bar move over them. To prevent the model from recognizing the black bar as an object, we also created a pretraining dataset that involved images of random items of different sizes and locations (shape objects and bars) passed them through the model before using our primary dataset to train.
Here is an example of images from our dataset:
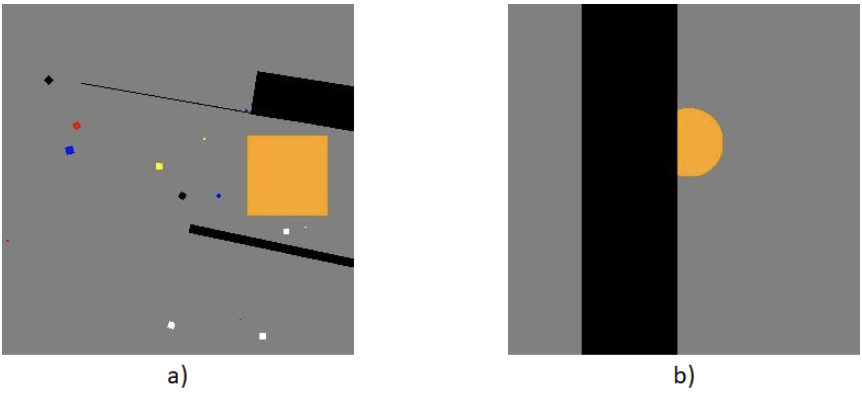
In a) we can see an example image from what we used in pretraining. In b) we can see an example frame that was passed in for training.
Finally, we compared the model's performance to how human subjects perform. We used data from 215 human subjects, where we showed them sample videos that were used for model testing and asked them to recognize the objects and their locations. What we found from the final model test data is that while the model is able to predict that something is occluded, it has a harder time predicting the exact location of the object the more it is occluded. However, we also found that humans have a similar error when predicting the location of an occluded object.
Conference Paper
This work was completed in Spring 2020, and was submitted over the summer to the 2020 MIT URTC
(Undergraduate Research Technology Conference), where it was accepted and was presented in October 2020.
The full paper with results is included below. It can also be viewed and downloaded here
or accessed through IEEE here.